Rubén Balbastre
“Todos los datos son iguales, pero algunos son más fáciles que otros”
Marzo de 2026
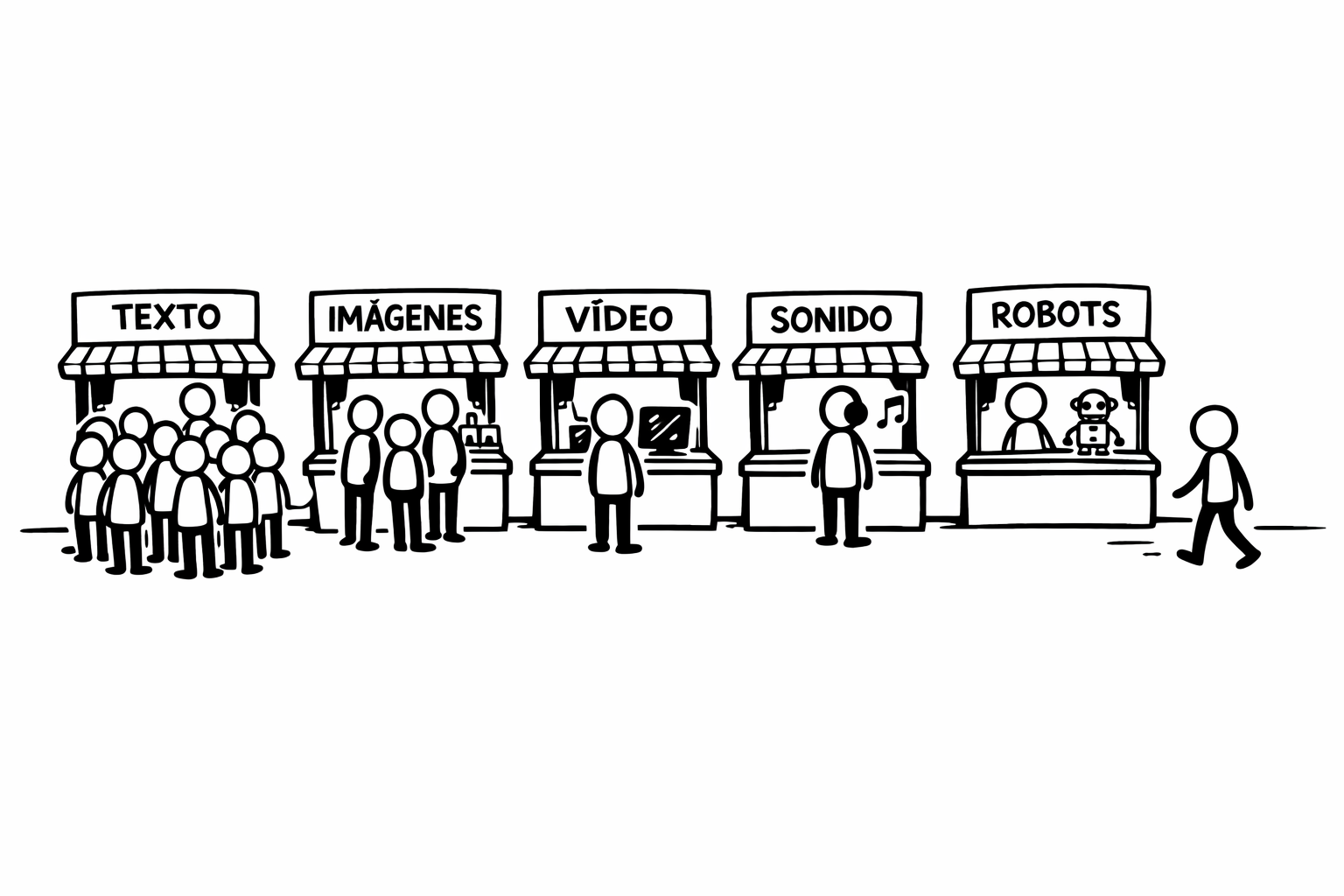
Cuando uno se adentra en el campo de la inteligencia artificial, descubre rápidamente que no todos los datos son iguales. Existen distintas modalidades —escalares, texto, imágenes, sonido y vídeo— y cada una tiene propiedades propias que obligan a diseñar modelos diferentes. Por eso no es raro que muchos investigadores se especialicen en una o dos: la naturaleza del dato condiciona profundamente tanto los algoritmos como su viabilidad en la práctica.
Sin embargo, más allá de esta clasificación, hay una forma especialmente útil de entender estas modalidades: analizarlas según su coste computacional y su rentabilidad económica. Este enfoque permite intuir hacia dónde se dirige la innovación. En lo que sigue, nos centraremos en tres casos clave: texto, imágenes y vídeo. El texto ha sido, probablemente, el gran ganador de los últimos años. Y no es casualidad. El lenguaje es una forma extremadamente eficiente de representar información: permite condensar ideas complejas en secuencias relativamente cortas de símbolos. A diferencia de una imagen, que contiene millones de píxeles, una frase puede capturar el mismo concepto con unas pocas palabras.
Además, los modelos de lenguaje transforman la generación en un problema relativamente manejable: predecir, paso a paso, la siguiente palabra dentro de un conjunto finito. Este encuadre ha permitido escalar sistemas de forma muy eficiente y aprovechar arquitecturas como los transformers.
Estas propiedades han tenido consecuencias prácticas importantes. Hoy, un único modelo puede realizar tareas muy diversas: redactar texto, programar, resumir información o responder preguntas. En particular, el código —que no deja de ser lenguaje estructurado— se ha convertido en uno de los casos de uso más productivos. Todo esto ha hecho que el texto no solo lidere en capacidades, sino también en adopción y monetización.
Las imágenes, en cambio, introducen un nivel de complejidad mayor. Generar una imagen no es elegir entre palabras, sino decidir el valor de millones de píxeles. En lugar de un conjunto discreto de opciones, el modelo debe operar en un espacio continuo y de alta dimensionalidad.
Modelos como los de difusión abordan este problema de forma indirecta: en vez de construir la imagen de una vez, parten de ruido y la van refinando progresivamente en múltiples pasos. Este proceso es potente, pero también costoso: generar una sola imagen puede requerir decenas de iteraciones, y el coste aumenta rápidamente con la resolución.
Por otro lado, modelos como CLIP han permitido conectar texto e imagen en un mismo espacio de representación. Esto ha abierto la puerta a sistemas capaces de generar imágenes a partir de descripciones o buscar imágenes mediante lenguaje. Sin embargo, estos enfoques también tienen limitaciones: dependen de grandes volúmenes de datos (con sesgos), les cuesta captar relaciones espaciales complejas y, en ocasiones, producen resultados que parecen correctos a primera vista pero fallan en detalles concretos. El vídeo añade otra capa de dificultad. No es solo una secuencia de imágenes, sino una secuencia que debe ser coherente en el tiempo. Un objeto no puede aparecer y desaparecer arbitrariamente; los movimientos deben tener continuidad y cierta plausibilidad física.
Esto implica que el modelo no solo genera imágenes, sino que debe mantener consistencia entre ellas. En la práctica, generar unos pocos segundos de vídeo supone producir y coordinar decenas o cientos de frames. El coste computacional, por tanto, no solo aumenta: se multiplica. Si además se añade audio, aparece un nuevo reto de sincronización.
En este contexto, resulta ilustrativo el caso de modelos recientes como Sora. Más allá del impacto inicial, estos sistemas ponen de manifiesto un problema clave: generar vídeo de alta calidad es extremadamente caro. Esto sugiere que, aunque la capacidad técnica avance rápidamente, convertirla en un producto sostenible es mucho más complejo. En muchos casos, estas tecnologías también cumplen una función estratégica: demostrar lo que es posible, incluso antes de que sea rentable a gran escala.
Otra de las grandes promesas del campo es la robótica, que puede entenderse como la integración de todas estas modalidades. Un robot avanzado debe ver su entorno, interpretar lo que ocurre, planificar acciones y ejecutarlas físicamente. Por ejemplo, reconocer una taza sobre una mesa, decidir coger y mover el brazo con precisión para hacerlo.
Algunas líneas de investigación intentan articular este proceso combinando modelos multimodales: primero interpretar la escena visual, después generar una secuencia de acciones y finalmente traducirla en movimiento. Sin embargo, llevar esto al mundo real sigue siendo difícil. A diferencia del software, la robótica introduce fricciones físicas: errores tienen consecuencias, los sistemas deben ser seguros y el desarrollo es más lento y costoso.
Por eso, aunque el potencial es enorme, parece poco probable que veamos avances disruptivos inmediatos. En un entorno donde la inversión busca resultados rápidos, es lógico que los recursos se concentren en áreas con retorno más claro, como el texto.
En conjunto, este recorrido sugiere una jerarquía bastante clara. El texto, por su naturaleza comprimida y discreta, ha permitido desarrollar sistemas eficientes y ampliamente adoptados. Las imágenes representan un desafío mayor, con costes más altos y limitaciones aún visibles. El vídeo, por su dimensión temporal, sigue siendo un terreno en desarrollo, con importantes barreras técnicas y económicas. Todo apunta a que, al menos en el corto y medio plazo, el progreso seguirá apoyándose principalmente en el texto.
Enlaces: